本文主要学习在linux glibc使用的ptmalloc2实现原理。
当前针对各大平台主要有如下几种堆内存管理机制:
dlmalloc – General purpose allocator
ptmalloc2 – glibc
jemalloc – FreeBSD and Firefox
tcmalloc – Google
libumem – Solaris
本文主要学习在linux glibc使用的ptmalloc2实现原理。
本来linux默认的是dlmalloc,但是由于其不支持多线程堆管理,所以后来被支持多线程的prmalloc2代替了。
linux平台*malloc本质上都是通过系统调用brk或者mmap实现的。
查看进程缺页中断次数
ps -o majflt,minflt -C process
Majflt major fault 大错误
Minflt minor fault 小错误
两个数值表示一个进程启动以来发生缺页中断次数
缺页中断:
1.软性中断:页缺失发生时,相关的页已经被加载进内存,但没有向mmu(memory management unit)注册
2.硬性中断:已被映射的虚拟地址没有被载入主存(当malloc分配了空间,但linux并未给创建空间的vma映射物理页,此时若对其进行操作会发生缺页中断)
发成缺页中断后,执行了那些操作?
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
1、检查要访问的虚拟地址是否合法
2、查找/分配一个物理页
3、填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
4、建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
Brk分配方式
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:

1、进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。
其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。
edata指针(glibc里面定义)指向数据段的最高地址。
2、进程调用A=malloc(30K)以后,内存空间如图2:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
你可能会问:只要把_edata+30K就完成内存分配了?
事实是这样的,edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3、进程调用B=malloc(40K)以后,内存空间如图3。
malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0),如下图:
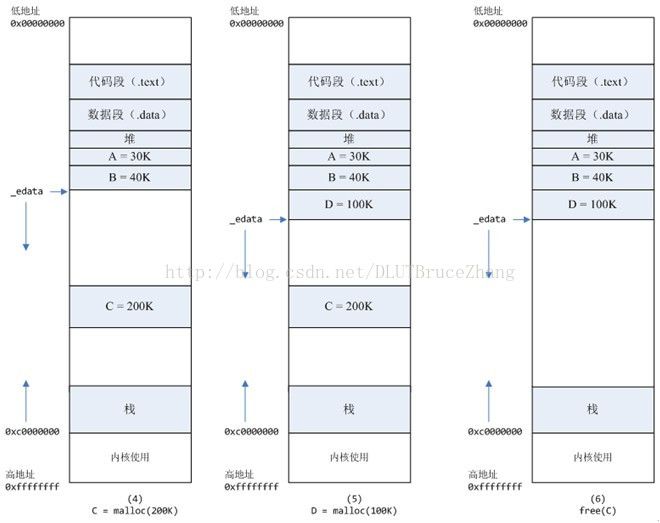
4、进程调用C=malloc(200K)以后,内存空间如图4:
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。
这样子做主要是因为::
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5、进程调用D=malloc(100K)以后,内存空间如图5;
6、进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放。
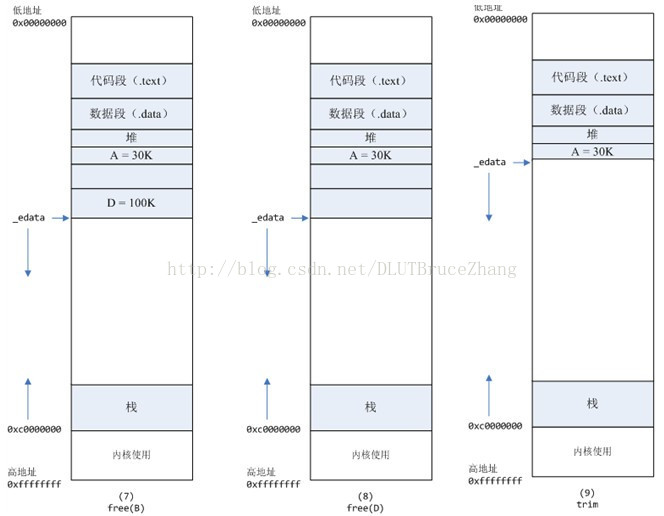
7、进程调用free(B)以后,如图7所示:
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8、进程调用free(D)以后,如图8所示:
B和D连接起来,变成一块140K的空闲内存。
9、默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
现在已经清楚了brk和mmap的基本分配方法
在malloc的内存小于128K时使用brk,即将_edata指针向高地址推,如果访问了新malloc的内容则会产生缺页中断
当aslr关闭时brk指针(即最初的_edata)会指向data/bss段的末尾(如图所示)
当aslr开启时,会再data/bss段的末尾随机增加一段偏移
大于128k时则使用mmap在堆栈之间的内存映射段分配出空间
1 | /* Per thread arena example. */ |


主线程运行后,这部分系统分配的内存叫做arena,这里大小为0x22000远比我们申请的1000字节多,这里之前就有了解过,操作系统在内核层面申请一部分内存,用户态使用时再从这部分内存中取,如果不够便再申请。
在主线程调用free之后:从内存布局可以看出程序的堆空间并没有被释放掉,原来调用free函数释放已经分配了的空间并非直接“返还”给系统,而是由glibc 的malloc库函数加以管理。它会将释放的chunk添加到main arenas的bin,这是一种用于存储同类型free chunk的双链表数据结构中。在这里,记录空闲空间的freelist数据结构称之为bins。之后当用户再次调用malloc申请堆空间的时候,glibc malloc会先尝试从bins中找到一个满足要求的chunk,如果没有才会向操作系统申请新的堆空间。
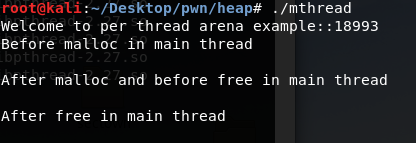

在thread1调用malloc之后:从输出结果可以看出thread1的heap segment已经分配完毕了,同时从这个区域的起始地址可以看出,它并不是通过brk分配的,而是通过mmap分配。
arena的个数是跟系统中处理器核心个数相关的,如下所示:
For 32 bit systems:
Number of arena = 2 number of cores + 1.
For 64 bit systems:
Number of arena = 8 number of cores + 1.
多Arena的管理
假设有如下情境:一台只含有一个处理器核心的PC机安装有32位操作系统,其上运行了一个多线程应用程序,共含有4个线程——主线程和三个用户线程。显然线程个数大于系统能维护的最大arena个数(2*核心数 + 1= 3),那么此时glibc malloc就需要确保这4个线程能够正确地共享这3个arena,那么它是如何实现的呢?
当主线程首次调用malloc的时候,glibc malloc会直接为它分配一个main arena,而不需要任何附加条件。+
当用户线程1和用户线程2首次调用malloc的时候,glibc malloc会分别为每个用户线程创建一个新的thread arena。此时,各个线程与arena是一一对应的。但是,当用户线程3调用malloc的时候,就出现问题了。因为此时glibc malloc能维护的arena个数已经达到上限,无法再为线程3分配新的arena了,那么就需要重复使用已经分配好的3个arena中的一个(main arena, arena 1或者arena 2)。那么该选择哪个arena进行重复利用呢?
1)首先,glibc malloc循环遍历所有可用的arenas,在遍历的过程中,它会尝试lock该arena。如果成功lock(该arena当前对应的线程并未使用堆内存则表示可lock),比如将main arena成功lock住,那么就将main arena返回给用户,即表示该arena被线程3共享使用。
2)而如果没能找到可用的arena,那么就将线程3的malloc操作阻塞,直到有可用的arena为止。
3)现在,如果线程3再次调用malloc的话,glibc malloc就会先尝试使用最近访问的arena(此时为main arena)。如果此时main arena可用的话,就直接使用,否则就将线程3阻塞,直到main arena再次可用为止。
这样线程3与主线程就共享main arena了。至于其他更复杂的情况,以此类推。
https://www.cnblogs.com/vinozly/p/5489138.html
https://www.cnblogs.com/alisecurity/p/5486458.html
https://sploitfun.wordpress.com/2015/02/11/syscalls-used-by-malloc/
https://www.freebuf.com/articles/system/91527.html
https://blog.csdn.net/qq_33438733/article/details/73149417